This post is on why real systems take the shapes they inevitably do.
Background
I have always wondered why the system design as a discipline has lacked the much required structure, even after so many years have observed that both real life system design thinking as well as the system design interview process are completely thought process driven and less structured thinking & framework driven, the main reason seems to be due to the extremely diverse, along with fast, ever changing & evolving mechanisms used to shape the systems under different requirements, constraints, pressures & trade-offs.
Generally one framework would fail to capture the variety of problem & solution space, so the approach followed is more of a library of concepts, patterns & learnings along with the ability to choose wisely, through the analytical thought process which is grounded in experience but driven by problem solving, logical thinking & exploratory learning.
Functional Intent Facing Non-Functional Reality
Large & complex systems do not fail because engineers lack the tools or patterns. They fail because intent and reality are either unknown or misaligned from beginning or over time.
Most design mistakes originate from collapsing what a system exists to do into how it is implemented, or from treating non-functional requirements as secondary constraints rather than primary forces. Over time, successful systems converge toward similar structural shapes – not because of shared technology stacks or common learning, but because they respond to the same underlying real life pressures.
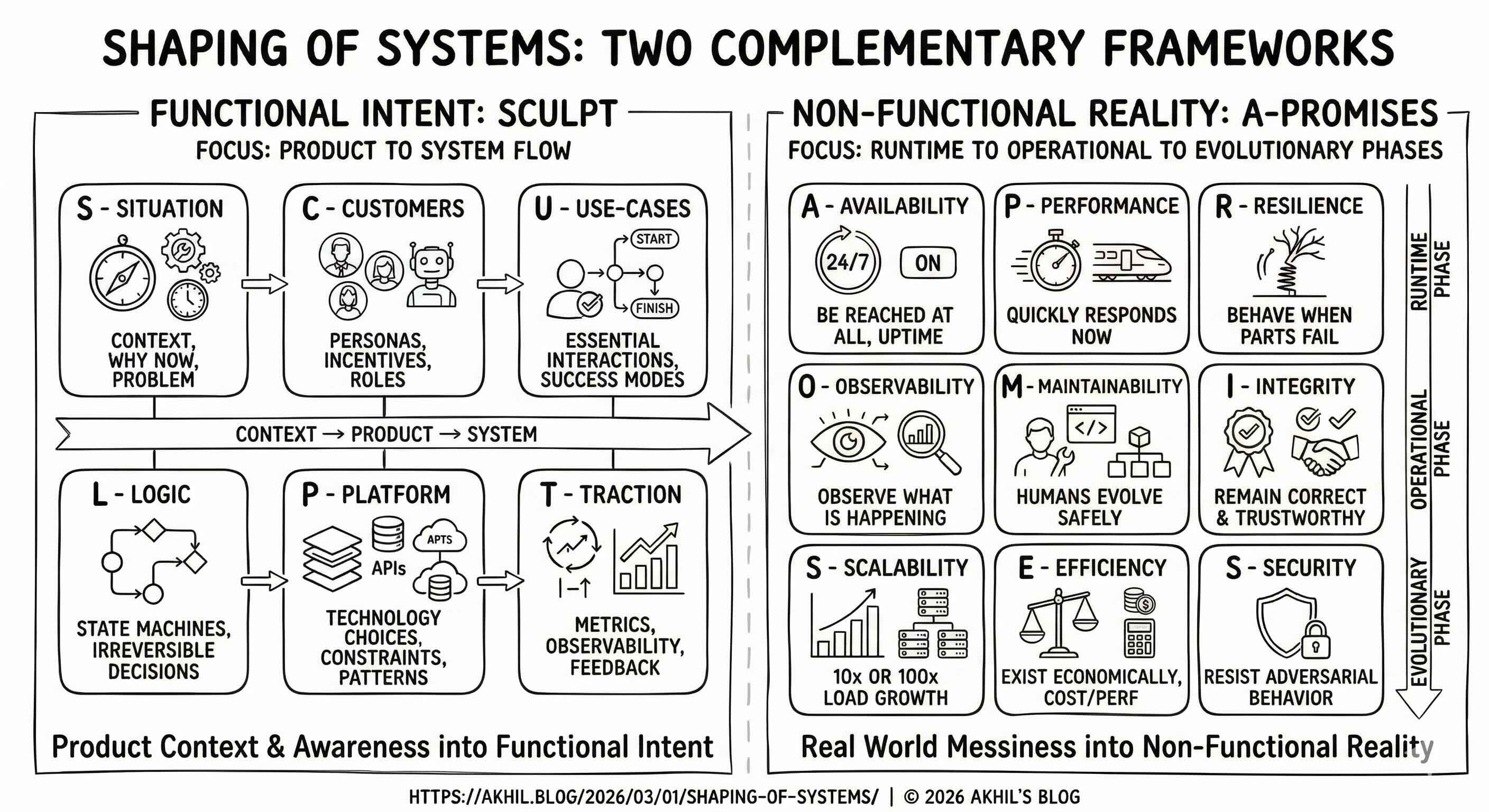
This essay proposes a way to reason about systems by separating functional intent from behavior under reality, then observing how their interaction determines architecture & design choices that shapes the system, and introduces two complementary lenses for reasoning about intent vs reality.
SCULPT describes functional intent – what the system exists to do.
A-PROMISES describes non-functional reality – how the system must behave to survive production.
Together, they can replace ad-hoc design intuition based only on experience with slightly more structured reasoning based intuition about tensions and trade-offs along with explicitly calling out assumptions.
Functional Intent: Why the System Exists
Every system is born to resolve a tension. Before databases, queues, caches, or APIs appear, there is a situation that needs to be addressed with the user experience in mind.
Across several domains, six recurring dimensions describe the functional intent. SCULPT is a simple framework to enforce disciplined reasoning – whybefore what, what before how, basically forces problem framing before design, and naturally transitions from product → system.
Situation – the contextual pressure that makes the system necessary.
Customers – the agents whose incentives shape behavior.
Use-cases – the minimal set of interactions that must succeed.
Logic – the irreversible decisions and state transitions.
Platform – the mechanisms chosen to make the logic executable.
Traction – the feedback loop that validates continued existence.
These dimensions are not a checklist, instead they describe a flow of causality: context produces users; users generate use-cases; use-cases demand logic; logic constrains platform; platform enables outcomes. To the contrary, when this flow is violated like when platform choices precede logic, or metrics precede intent, then systems become brittle.
Core Question
High Level Areas
Important Questions
Blind Spots & Pitfalls
S – Situation
Why does this system need to exist now, and what problem makes it unavoidable?
Business context and strategic goals. Market or operational constraints. Regulatory or compliance boundaries. Explicit scope and out-of-scope definition. Time horizon and urgency.
What triggered this initiative – growth, failure, regulation, or opportunity? What happens if we build nothing? Who is the economic buyer and what do they measure? What is explicitly out of scope, and why? Is this a greenfield build or a migration from something existing?
Treating the situation as obvious and skipping straight to features. Defining scope so broadly that every solution looks valid. Ignoring regulatory or compliance constraints until they block deployment. Assuming the business context won’t change during the build. Confusing the stated problem with the actual problem – stakeholders often describe symptoms, not causes.
C – Customers
Whose incentives, constraints, and behaviors will shape how the system must work?
User personas and segments. Internal versus external consumers. Human versus machine callers. Power users versus casual users. Jobs-to-be-done and motivations
Who are the distinct user types, and how do their goals conflict? Which users generate load versus consume value? Are there machine callers (APIs, internal services) with different SLAs? What does the worst-case user look like (adversarial, confused, high-volume)? How do user segments grow or shift over time?
Designing for “users” as a monolith when segments have conflicting needs. Forgetting internal operators and support teams as first-class users. Ignoring the adversarial user – bots, scrapers, abusers. Optimizing for power users while alienating the majority. Assuming today’s user mix is tomorrow’s user mix.
U – Use-cases
What are the essential interactions that must succeed for the system to justify its existence?
Core use-cases that drive primary value. Secondary and edge-case scenarios. Failure scenarios as first-class requirements. Prioritization criteria. Read versus write path decomposition.
Which 2–3 use-cases would make this system a success if nothing else worked? What failure modes must be handled gracefully versus allowed to surface? Which use-cases change design decisions, and which are cosmetic? What does the cold-start experience look like? Are there time-sensitive use-cases (on-sale moments, peak hours)?
Listing features instead of problems. Including use-cases that don’t materially change design decisions. Ignoring failure and degradation as use-cases. Treating all use-cases as equally important instead of ruthlessly prioritizing. Designing for the happy path and discovering edge cases in production.
L – Logic
What are the irreversible decisions, state transitions, and behavioral rules the system must enforce?
State machines and lifecycle transitions. Read and write path separation. Synchronous versus asynchronous processing boundaries. Ordering, idempotency, and retry semantics. Workflow orchestration versus choreography.
What state transitions are irreversible, and what are the consequences of getting them wrong? Where does the system need strong consistency versus eventual consistency? Which operations must be synchronous (user-blocking) versus asynchronous (background)? How are concurrent mutations handled – last-write-wins, optimistic locking, CRDTs? What happens when a multi-step workflow fails midway?
Treating logic as “just business rules” when it’s actually distributed systems coordination. Assuming synchronous processing when asynchrony would reduce coupling. Ignoring idempotency until duplicate processing causes data corruption. Conflating workflow orchestration (centralized) with choreography (event-driven) without understanding trade-offs. Designing state machines implicitly instead of explicitly – leading to impossible states in production.
P – Platform
What technology choices make the logic executable, and what constraints do they introduce?
Data stores and access patterns. Caching layers and invalidation strategies. Messaging, streaming, and event infrastructure. Deployment topology and service boundaries. Third-party integrations and external dependencies.
What are the dominant access patterns – point lookups, range scans, full-text search, time-series? Does the data model favor relational, document, columnar, or graph storage? Where do caches add value, and what is the invalidation strategy? Are service boundaries aligned with team boundaries and deployment cadence? Which components are on the critical path versus best-effort?
Choosing technologies before understanding logic and access patterns. Introducing caching without a coherent invalidation strategy. Drawing microservice boundaries around technical layers instead of business capabilities. Underestimating the operational cost of every new technology in the stack. Treating third-party APIs as reliable when they are the most common source of production incidents.
T – Traction
How will you know the system is succeeding, and what feedback loops drive iteration?
Success metrics tied to business outcomes. Operational health indicators. Adoption and usage signals. Latency, error rate, and throughput SLOs. Feedback loops that inform product and engineering decisions.
What single metric would prove this system is working? Are there leading indicators that predict success before lagging metrics move? What SLOs will trigger engineering action when breached? How will you distinguish system failure from product failure? What instrumentation is needed from day one versus added later?
Defining metrics after launch instead of baking them into the design. Tracking vanity metrics that don’t connect to business outcomes. Missing the feedback loop – metrics that no one monitors or acts on. Conflating system health (latency, errors) with product health (engagement, conversion). Setting SLOs without understanding the cost of meeting them.
Non-Functional Reality: How the System Survives & Thrives
Functional intent alone does not shape real systems but non-functional reality also intervenes through constraints that are always present but rarely obvious. Non-functional requirements are not “quality attributes” but rather are “underlying forces” to be reckoned with & thought through when building systems which can survive over space & time, and they can be thought of as the promises your system makes to its users/operators & breaking these promises generally has consequences.
Across several domains, there are few recurring dimensions that describe non-functional reality in a comprehensive way. The acronym A-PROMISES forces explicit trade-offs instead of implicit assumptions, with intentional ordering of business survivability first, infra rigor second, focusing on increasing severity gradient - first survive, then operate, then guarantee correctness, then grow sustainably, then defend.
Availability – whether the system can be reached at all.
Performance – how quickly the system responds now.
Resilience – how it behaves when parts fail.
Observability – what is happening can be observed.
Maintainability – whether humans can evolve it safely.
Integrity – whether it remains correct and trustworthy.
Scalability – what happens when load grows 10x or 100x.
Efficiency – whether it can exist economically.
Security – whether it resists adversarial behavior.
This also follows runtime → operational → evolutionary phase / stage wise priorities cleanly, which is generally the common prioritization flow across many system life-cycles.
Phase
Concerns
Dimensions
Runtime
Can users reach it? How fast? What when it breaks?
A - Availability, P - Performance, R - Resilience
Operational
Can you see what’s happening? Can you change it safely? Is it correct & trustworthy?
O - Observability, M - Maintainability, I - Integrity
Evolutionary
Does it scale? Can it exist economically? Does it resist attack and abuse?
S - Scalability, E - Efficiency, S - Security
Generally most of the architectural decisions are a compromise among these dimensions – when a system favors availability, it weakens integrity, when it optimizes performance, it often sacrifices maintainability, similarly observability is runtime architectural necessity, cannot be an operational afterthought. These trade-offs are unavoidable; denying them only hides them until failure hits.
Core Question
High Level Areas
Important Questions
Blind Spots & Pitfalls
A – Availability
Can users reach the system when they need it?
SLOs, SLAs, and uptime targets. Fault tolerance and redundancy. Graceful degradation strategies. Fail-open versus fail-closed policies. Dependency availability chains.
What availability target is required (99.9%, 99.99%), and what does the gap cost? Is partial availability acceptable, or is it all-or-nothing? Should the system fail-open (allow uncertain requests) or fail-closed (block when uncertain)? Which dependencies are on the critical path, and what is the compound availability? What is the planned maintenance strategy – rolling updates, blue-green, canary?
Quoting an SLO without understanding the error budget math. Assuming availability of dependencies without measuring compound probability. Treating all features as equally critical – not all paths need the same uptime. Ignoring regional or network-level failures in availability planning. Designing for steady-state availability but not for recovery speed after failures.
P – Performance
How fast does the system respond under current load, and how predictable is that response?
Latency targets across percentiles (P50, P95, P99). Throughput capacity. Tail latency behavior and amplification. Synchronous versus asynchronous path performance. User-perceived versus system-measured performance.
What latency is acceptable at P50 versus P99, and who defines those targets? Where does tail latency amplification occur (fan-out, dependent calls, GC pauses)? Is the bottleneck compute, I/O, network, or coordination? What is the difference between system latency and user-perceived latency? Are there batch versus real-time paths with different performance profiles?
Optimizing average latency while ignoring P99 tail behavior. Measuring server-side latency but missing client-perceived delays (DNS, TLS, rendering). Assuming linear performance scaling when real systems have cliffs. Tuning for throughput at the expense of latency variance. Confusing “it’s fast on my machine” with “it’s fast under production load.”
R – Resilience
What happens when things break – does the system degrade gracefully or cascade into failure?
What is the blast radius of each component’s failure? How does the system behave when a dependency is slow versus down? Are retries safe, or do they amplify failure (retry storms)? What is the disaster recovery strategy – active-active, active-passive, backup-restore? How long can the system operate in a degraded mode before it becomes unacceptable?
Confusing resilience with availability – “it’s up” is different from “it handles failure well.” Implementing retries without backoff or jitter, causing cascading overload. Missing the difference between a dependency being down (fast failure) versus slow (resource exhaustion). Testing happy-path resilience but never practicing disaster recovery. Assuming the network is reliable, latency is zero, and bandwidth is infinite.
O – Observability
Can you understand what the system is doing, why it’s misbehaving, and where to intervene?
Structured logging with correlation. Distributed tracing across service boundaries. Metrics pipelines and dashboards. Alerting strategies and escalation. Debuggability and root-cause analysis tooling.
Can you trace a single request across every service it touches? What is the cardinality cost of your metrics – are you tracking enough dimensions without exploding storage? How quickly can an on-call engineer diagnose a novel failure? Are alerts actionable, or do they create noise that gets ignored? What is the observability cost as a percentage of infrastructure spend?
Treating observability as “we have logging” when logging without structure is just noise. Adding distributed tracing after the architecture is set, making instrumentation painful and incomplete. Alert fatigue from thresholds that fire on non-actionable conditions. Underestimating observability infrastructure cost – it often becomes 10–30% of total spend. Building dashboards that show system health but not business health. Observability that works in steady state but fails during the incidents when you need it most.
M – Maintainability
Can humans safely evolve, deploy, and operate this system over its lifetime?
Deployment safety – blue-green, canary, rollback. Schema evolution and backward compatibility. Feature flagging and progressive rollout. Operational runbooks and incident playbooks. Team cognitive load and onboarding cost.
How long does it take a new engineer to make a meaningful contribution? Can you deploy to production without fear – is rollback fast and safe? How are database schema changes handled without downtime? Is the system’s complexity proportional to the problem it solves? What is the bus factor – how many people truly understand the system?
Optimizing for build speed while ignoring the maintenance tax that follows. Assuming the team that built it will maintain it forever. Designing schemas that are efficient today but impossible to migrate tomorrow. Accumulating operational debt – no runbooks, no playbooks, tribal knowledge only. Measuring engineering productivity by feature velocity without accounting for incident burden.
I – Integrity
Is the data correct, consistent, and trustworthy at all times?
Consistency model selection (strong, eventual, causal). Idempotency guarantees. Write ordering and conflict resolution. Data durability and corruption prevention. Audit trails and data lineage.
What consistency model does each use-case actually require – are you paying for strong consistency where eventual would suffice? Which operations must be idempotent, and how is idempotency enforced (keys, deduplication, deterministic logic)? How are conflicting concurrent writes resolved – last-write-wins, merge, reject? What is the data durability guarantee, and how is it validated (not just assumed)? Can you prove the system state is correct after a failure – is there an audit trail?
Defaulting to strong consistency everywhere when most reads tolerate staleness. Assuming idempotency without explicitly designing for it – duplicate processing is the most common data corruption source. Conflating durability (data is saved) with integrity (data is correct). Ignoring ordering constraints until race conditions corrupt production data. Treating consistency as a database property when it’s actually a system-wide design decision spanning caches, queues, and services.
S – Scalability
What happens when load grows 10x or 100x – does the architecture bend or break?
Horizontal versus vertical scaling strategy. Sharding and partitioning approaches. Stateless versus stateful service design. Back-pressure and load shedding mechanisms. Growth modeling and capacity planning.
What is the expected growth trajectory – linear, exponential, or spiky? Which components are stateful, and how does state limit horizontal scaling? What is the sharding or partitioning strategy, and what happens when you need to re-shard? Where are the scaling bottlenecks – databases, coordination points, shared resources? How does the system shed load gracefully when capacity is exceeded?
Confusing performance with scalability – a system can be fast today and break at 10x. Designing stateful services without a plan for state redistribution. Choosing a sharding key that creates hot spots under real-world access patterns. Scaling compute without scaling the data layer, creating new bottlenecks. Assuming cloud auto-scaling solves the problem when the real constraint is architectural (shared locks, single-writer, coordination).
E – Efficiency
Can the system exist economically at the scale it needs to operate?
Cost per request, per user, and per transaction. Resource utilization and waste. Infrastructure cost scaling curves. Build versus buy trade-offs. Unit economics and margin impact.
What does it cost to serve one request, one user, or one transaction – and how does that scale? Where is the system wasting resources – over-provisioned instances, unused storage, redundant processing? Is the cost curve linear, sub-linear, or super-linear with growth? What is the total cost of ownership including operations, on-call, and incident response? Are there architectural choices that trade higher upfront cost for lower marginal cost?
Ignoring cost until the monthly bill arrives and triggers an emergency optimization sprint. Optimizing compute cost while ignoring data transfer, storage, and third-party API costs. Treating efficiency as purely an infrastructure concern when architectural choices (fan-out, replication factor, retention) dominate spend. Over-engineering for efficiency at low scale when engineering time is more expensive than infrastructure. Failing to model cost scaling curves – many systems are cheap at launch and unsustainable at target scale.
S – Security
How does the system resist abuse, compromise, and unauthorized access?
Authentication and authorization models. Data privacy and encryption (at rest, in transit). Abuse prevention and rate limiting. Tenant isolation in multi-tenant systems. Threat modeling and attack surface management.
What is the authentication model, and how are tokens/sessions managed and revoked? How is authorization enforced – at the gateway, service level, or data level? What data is sensitive (PII, financial, health), and how is it classified and protected? How is the system protected against abuse – bots, scraping, credential stuffing, DDoS? In a multi-tenant system, how is tenant data isolated, and what happens if isolation breaks?
Treating security as a bolt-on audit instead of a structural design property. Implementing authentication without thinking about authorization granularity. Encrypting data in transit but leaving it unencrypted at rest (or vice versa). Designing abuse prevention reactively instead of building it into the admission path. Assuming tenant isolation is guaranteed by application logic when infrastructure-level leaks are possible. Ignoring supply-chain security – dependencies, CI/CD pipelines, and secrets management.
How Functional Intent Interact Non-Functional Reality ?
System architecture & design emerges at the intersection of what must be done (intent) & what cannot be avoided (reality). SCULPT ensures building the right system while A-PROMISES ensures that system survives reality. SCULPT shows problem shaping and product awareness whileA-PROMISES shows real world constraints creating pressures & challenges.
Few Structural Principles That Emerge
Irreversible actions demand early, explicit gating. Wherever a decision cannot be undone – admitting a request, selling a seat, confirming a write, the system must decide before work begins, not after. Late enforcement means the damage is already done. This is why rate limiters sit at the ingress, ticketing systems lock inventory before payment, and KV stores require quorum acknowledgment before confirming writes. The earlier the gate, the smaller the blast radius. The corollary: every gate must declare its assumptions explicitly, because implicit assumptions in irreversible paths become production incidents.
Latency shapes trust more than correctness. Users forgive stale data faster than they forgive slow responses. A home listing platform showing slightly outdated prices in 200ms builds more confidence than one showing perfect prices in 2 seconds. A KV store with predictable P99 latency gets adopted; one with better average latency but occasional 5-second spikes gets replaced. This is counterintuitive for engineers who optimize for correctness first, but perception is the product. Latency is not a technical metric – it is a user-facing promise.
Asynchrony is earned by tolerating delay; synchrony is reserved for irreversibility. Systems do not “choose” async for performance. Asynchrony appears precisely where correctness can tolerate temporal delay – ranking pipeline updates, index refreshes, replication propagation. Synchrony persists wherever the cost of a stale or wrong decision is unrecoverable – token accounting in a rate limiter, seat reservation in ticketing, leader election in a KV store. The boundary between sync and async is not a performance optimization; it is a correctness boundary.
State machines emerge wherever reversibility disappears. When a system cannot undo a transition – available → reserved → sold, or proposed → committed → replicated – implicit state tracking silently introduces impossible states. Explicit state machines make transitions auditable, retries safe, and failures recoverable. Ticketing systems need them because overselling is catastrophic. KV stores need them because replication state determines data safety. The absence of an explicit state machine is not simplicity; it is hidden complexity waiting to surface.
Caches exist wherever speed outweighs freshness but invalidation determines whether they help or hurt. Every cache is a bet that stale data is acceptable for some window. Home listing availability caches bet that a few seconds of staleness is worth sub-100ms lookups. Rate limiter local caches bet that approximate counts are worth avoiding network round-trips. The cache itself is easy. The invalidation strategy – when staleness becomes unacceptable is where systems break. A cache without an explicit invalidation contract is a consistency bug with a delay timer.
Partial availability beats total failure in almost every system but the boundary must be designed, not discovered. A home listing platform returning cached results during a ranking outage is degraded but useful. A rate limiter in fail-open mode during a Redis outage is imperfect but survivable. The principle is universal, but the boundary – which functions degrade, how far, and what the user sees – must be an explicit design decision. Systems that discover their degradation modes in production discover them badly. The question is never “should we degrade gracefully?” – it is “what does graceful look like, and have we tested it?”
Observability is a prerequisite for every other property, not a feature added after them. You cannot improve availability that you cannot measure. You cannot debug resilience failures you cannot trace. You cannot optimize efficiency you cannot attribute. Across all four systems, observability determines whether other properties are real or aspirational. A KV store without partition-level metrics cannot rebalance safely. A ticketing system without end-to-end purchase tracing cannot diagnose allocation failures. Observability is not instrumentation – it is the ability to ask novel questions about system behavior and get answers fast enough to act.
Systems fail socially before they fail technically. The rate limiter that no one knows how to reconfigure safely. The ranking pipeline that only one engineer understands. The KV store cluster that no one has practiced recovering from a partition. Technical failures have technical fixes. Organizational failures – knowledge silos, missing runbooks, untested recovery procedures, schemas that can’t evolve – compound silently until they become the actual cause of outages. Maintainability is not a quality attribute; it is the system’s immune system.
These principles are not just patterns to help pick an existing solution to be reused to speed up design; but they are outcomes of pressure seen in many system problems to be re-applied.
Designing Systems, Not Deriving Solutions
The mistake in many system designs is treating design & architecture as composition rather than response. Systems are not assembled from design pieces picked from the past; they are shaped.
Functional intent defines why a system must exist. Non-functional reality defines how it is allowed to exist. Architecture generally is the compromise between the two.
Frameworks and diagrams are useful only insofar as they help surface these tensions. When they obscure them, they become harmful.
A well-designed real life system does not appear simple & elegant, instead it appears inevitable because every part exists for a reason that reality enforces.
Good systems are not optimized on every dimension, they mirror reality–about constraints, about failure, and about trade-offs.
System design, at its core, is not about inventing structures, it is about recognizing which structures reality will eventually force – and getting there deliberately with thinking, rather than accidentally with iterations of trial & error.
Four real life examples
Consider four systems that appear unrelated mostly: a rate limiter, a home listing platform, an event ticketing system, and a key-value store, even though their surface areas differ, but their shapes are governed by the same underlying pressures, constraints & laws. Before applying the frameworks, it’s important to know what makes each problem fundamentally different.
Dimension
Rate Limiter – Admission Control as a First-Class System
Home Listing Platform – Discovery Under Uncertainty
Event Ticketing – Atomic Allocation Under Contention
Key-Value Store – Predictable Semantics at Scale
Problem
Shared infrastructure must survive uncoordinated demand, and protection must occur before damage propagates.
Discovery must connect exploratory intent with volatile supply, while preserving marketplace balance.
Scarce inventory under synchronized demand requires deterministic allocation, not best-effort throughput.
Latency-sensitive access with simple semantics becomes complex only because of scale and failure.
Why Is It Hard ?
Damage propagates faster than detection. Shared infrastructure cannot distinguish malicious intent from accidental overload in real time. The only safe option is to control admission before work is done.
Discovery systems must tolerate ambiguity – users do not know what they want, supply changes constantly, and relevance is probabilistic. This forces a fundamental separation: retrieval is not ranking, and ranking is not presentation.
Demand is synchronized, inventory is finite, and failure is irreversible. Overselling is not a degraded state – it is a fatal one. This forces the system into explicit state machines where time (TTLs) becomes a first-class concept.
The interface is trivial; the reality is not. Distribution introduces unavoidable conflicts: consistency versus availability, durability versus latency, coordination versus throughput. These tensions produce canonical structures that no shortcut can avoid.
Defining Architectural Property
Synchronous gating at the ingress. Because admission decisions are irreversible, latency constraints are extreme. Because fairness requires memory, shared state is unavoidable. Because blocking the wrong request may be worse than allowing a bad one, availability and correctness remain in permanent tension.
Multi-stage pipelines: constraint filtering, candidate generation, re-ranking, and assembly. Asynchrony appears because freshness cannot block responsiveness. Caching appears because perceived latency defines trust. Availability favors partial correctness – showing something reasonable now beats everything perfectly later.
Conservative architecture by necessity. Performance is subordinate to predictability. Resilience focuses on replay and compensation. Integrity dominates all other concerns. The architecture privileges correctness over throughput and fairness over speed.
A machine for containing complexity, not eliminating it. Routing minimizes coordination. Replication manages failure. Compaction manages cost. The architecture exists because no single-node solution survives the combination of scale, failure, and latency requirements.
Key Insight
The architecture is minimal but rigid: early placement, fast state access, deterministic decisions. It does not evolve toward flexibility; it evolves toward predictability.
Integrity becomes perceptual rather than absolute. The system’s correctness is measured by user satisfaction, not by data precision alone. Partial correctness is a feature, not a bug.
Complexity is accepted because simplification would destroy trust. Every shortcut in this domain has a name: it’s called “overselling.”
Maintainability becomes existential. The system will outlive its creators. Tooling and observability are not auxiliary features; they are survival mechanisms.
Applying the framework to the four examples
The following tables apply SCULPT and A-PROMISES to each example. Each cell captures the design reasoning - not so much implementation details, but more of tensions & decisions that shape architecture.
SCULPT – Functional Intent
SCULPT
Rate Limiter
Home Listing Platform
Event Ticketing
Key-Value Store
S – Situation
Shared infrastructure must survive uncoordinated demand. Abuse and accidental overload are indistinguishable at runtime. Protection must occur before downstream damage propagates – reactive detection is too late.
Discovery must connect demand with sparse, volatile supply. User intent is exploratory and imprecise, not transactional. Marketplace health depends on balanced exposure – favoring any side destroys liquidity.
Demand is highly synchronized and often adversarial (bots, scalpers). Overselling is catastrophic and publicly irreversible. Perceived fairness matters as much as allocation correctness – unfairness damages brand trust.
Many systems depend on predictable, low-latency data access. The store acts as a foundational infrastructure primitive – its failures cascade everywhere. Horizontal scaling with predictable behavior is non-negotiable.
C – Customers
Callers vary widely in intent, quality, and trust level. Internal consumers assume stability and fast failure; external consumers assume nothing. Security and operations teams require real-time visibility and policy control.
Seekers optimize for relevance and speed of discovery. Suppliers (owners, agents) optimize for visibility and yield. Internal ranking and pricing systems optimize for marketplace leverage and long-term health.
Buyers optimize for success probability – they want certainty, not options. Organizers optimize revenue, fairness, and brand reputation. The platform itself optimizes throughput and trust simultaneously.
Callers expect uniform, well-documented semantics regardless of scale. Platform teams expect operability, debuggability, and safe upgrades. Workloads range from low-latency point lookups to high-throughput batch scans.
U – Use-cases
Enforce fairness without centralized coordination. Absorb traffic bursts without penalizing steady-state callers. Degrade gracefully under overload – shedding load is better than crashing.
Narrow large candidate sets efficiently based on multi-dimensional intent. Support iterative refinement as users clarify what they want. Surface supply without overwhelming users – relevance over completeness.
Allocate scarce inventory atomically under extreme contention. Handle demand spikes deterministically – no probabilistic allocation. Support the full post-purchase lifecycle: cancellation, transfer, refund.
Support fast point lookups as the primary access pattern. Tolerate concurrent reads and writes without coordination overhead. Scale access horizontally without adding semantic complexity.
L – Logic
Convert continuous demand into discrete token allowances. Make admission decisions synchronously under uncertainty – there is no time for deliberation. Maintain correctness under high concurrency without distributed locking.
Transform raw listings into ranked, personalized candidates. Combine geo-spatial, preference, and policy constraints in a composable pipeline. Maintain stable ordering across user interactions to preserve trust.
Temporarily reserve inventory under contention using TTL-based locks. Transition inventory through well-defined, auditable states (available → held → sold). Guarantee irreversible finalization – once sold, the seat cannot be double-allocated.
Map keys to partitions deterministically using consistent hashing. Coordinate replicas under failure while preserving the chosen consistency model. Resolve conflicts predictably – last-write-wins, vector clocks, or application-level merge.
P – Platform
Fast shared state store with atomic counters (Redis, in-memory). Placed on the critical ingress path – gateway, sidecar, or middleware. Regional versus global enforcement based on consistency requirements.
Hybrid of index-based retrieval (Elasticsearch, OpenSearch) and caching layers. Asynchronous enrichment and ranking pipelines. Strong separation of read path (search, browse) and write path (listing updates).
Strongly consistent transactional core for inventory management. Fast cache layer for availability lookups to reduce database pressure. External payment and notification services on the critical purchase path.
Partitioned storage engine with log-structured writes (LSM trees). Replication protocol defining the consistency-availability trade-off. Cluster membership and coordination service for topology management.
T – Traction
Reduction in cascading downstream failures. Stable and predictable latency under variable load. Measurable improvement in caller experience – fewer timeouts, fewer retries.
Improved discovery efficiency – higher engagement per search session. Healthier supply-demand matching measured by contact and conversion rates. Time-to-first-meaningful-result as a leading indicator.
Successful allocation rate under peak synchronized demand. Lower drop-off during checkout – a proxy for system reliability and UX clarity. Trust in the platform’s fairness, measured by repeat usage and complaint rates.
Predictable latency envelopes maintained across percentiles. High availability under node churn, traffic spikes, and cluster operations. Widespread adoption across internal services – the ultimate vote of confidence.
A-PROMISES – Non-Functional Reality
A-PROMISES
Rate Limiter
Home Listing Platform
Event Ticketing
Key-Value Store
A – Availability
Protection must not become a single point of failure. The fail-open versus fail-closed decision is fundamental – incorrect blocking may be worse than temporary overload. Partial protection (some rules enforced) is better than total protection failure.
Partial search results preserve user momentum better than empty pages. Cached fallback paths ensure read availability even during index lag. Read-path availability is prioritized over write-path freshness.
Purchase path availability strictly dominates browsing availability. Queue-based admission control prevents uncontrolled concurrency from degrading the critical path. Failure semantics must be explicit and final – ambiguous failures are worse than clear rejections.
Availability competes directly with consistency – the CAP theorem is not theoretical here. Callers must understand availability guarantees without reading documentation. Maintenance operations (upgrades, rebalancing) must not disrupt active traffic.
P – Performance
Admission decisions must complete faster than the downstream calls they protect – if the limiter adds significant latency, it defeats its purpose. Tail latency directly impacts caller success and retry behavior. Hot-key concentration is unavoidable and must be engineered for.
Perceived latency shapes user trust more than actual system latency. Fast feedback loops (instant filter updates, smooth pagination) matter more than completeness. Sub-300ms search latency is the threshold below which users feel the system is responsive.
Latency spikes during on-sale moments translate directly to lost sales and customer frustration. Predictability matters more than raw speed – consistent 200ms is better than variable 50–500ms. Tail latency at P99 defines the user experience for the most engaged buyers.
P99 read and write latency defines the store’s usability as infrastructure. Throughput must scale linearly with added capacity – sub-linear scaling is an architecture problem. Latency variance is more damaging than latency mean – callers set timeouts based on worst-case expectations.
R – Resilience
Dependency failures (shared state store outages) are common, not exceptional – the system must have a degraded-mode plan. Recovery must be automatic and fast – manual intervention during an outage compounds the problem. Bypass rules for known-safe traffic can prevent false positives during limiter degradation.
Ranking service failures must not block basic search – retrieval and ranking degrade independently. Search index lag is inevitable; the read path must tolerate stale data without corrupting user experience. Backpressure from listing update storms must not cascade into search latency.
External payment gateways will fail mid-transaction – the purchase flow must be replay-safe and compensating. Demand spikes must be absorbed through controlled admission, not allowed to amplify into cascading failures. State transitions must be idempotent so that retries after partial failures don’t corrupt inventory.
Individual nodes fail routinely at scale – this is normal operations, not an incident. Re-replication speed after node loss determines the window of vulnerability. Network partitions must resolve toward a predictable, documented state – split-brain is existential.
O – Observability
Operators must see in real time which policies are firing, which tenants are being throttled, and whether the limiter itself is healthy. Debugging must be deterministic – given the same state and request, the decision must be reproducible. Metrics must distinguish between legitimate throttling (working correctly) and false positives (harming good traffic).
Search pipeline observability must span retrieval, ranking, and assembly – partial visibility produces misleading root causes. Ranking experiments require isolated metrics to detect regressions without cross-contamination. Listing freshness and index lag must be visible as leading indicators, not discovered during user complaints.
End-to-end purchase tracing from admission through payment to confirmation is non-negotiable. Seat allocation decisions must be auditable after the fact – “why did this person not get a ticket?” must be answerable. Real-time dashboards during on-sale events must show queue depth, allocation rate, and failure reasons.
Request-level tracing must cross client, routing, replica, and storage engine boundaries. Cluster-level metrics (replication lag, partition balance, compaction backlog) define operational health. Capacity forecasting depends on observability data – without it, scaling is reactive and expensive.
M – Maintainability
Rate limiting policies change faster than code deploys – dynamic configuration without restarts is essential. Per-tenant and per-endpoint policies must be composable without combinatorial explosion. Operational tooling must support safe policy rollout with rollback.
Ranking model iteration speed directly determines competitive advantage – slow experimentation means stale relevance. Feature flagging must be granular enough to test ranking changes on user segments without global risk. Debuggable search pipelines require clear stage boundaries and intermediate result inspection.
Business rules (pricing tiers, fee structures, allocation policies) vary per event and change frequently. Schema migrations for inventory and transaction tables must be zero-downtime. Operational dashboards must scale with the number of concurrent events – per-event isolation without per-event engineering effort.
Cluster rebalancing must be automated, non-disruptive, and observable. Schema evolution (new data formats, compression changes) must be backward compatible across cluster versions. Humans must be able to understand cluster state without reading code – operational tooling is a survival requirement.
I – Integrity
Token and counter accounting must be accurate under concurrency – miscounts silently erode protection or fairness. Race conditions in allowance checking are more dangerous than outages because they fail silently. Window boundary semantics (fixed versus sliding) must be provably correct – subtle bugs here are nearly undetectable.
No duplicate listings should appear in results – deduplication failures confuse users and erode trust. Pricing and availability must be consistent between search results and detail pages – stale data creates broken promises. Ranking inputs (signals, features) must be consistent across pipeline stages to produce stable, explainable ordering.
No overselling under any condition – this is the single inviolable invariant. Ticket allocation must be exactly-once, provable, and auditable after the fact. Seat map representation must be authoritative – discrepancies between what users see and what the system knows are catastrophic.
The chosen consistency model (strong, eventual, causal) defines the system’s contract with callers – violating it silently is worse than downtime. Write ordering correctness must be maintained through failures, not just during steady state. Data corruption prevention (checksums, write validation) is foundational – undetected corruption propagates irreversibly.
S – Scalability
Hot-key concentration creates non-uniform load that defeats naive horizontal scaling. Cross-region enforcement requires either state replication (costly, consistent) or regional independence (cheaper, approximate). Global rate limiting at millions of QPS requires sharding the counter space without losing fairness.
Index growth competes with query latency – larger indexes mean slower searches unless partitioned carefully. Re-ranking cost grows with candidate set size – relevance versus latency is a scaling trade-off. User growth amplifies both read load (searches) and write load (interactions, signals), but asymmetrically.
On-sale traffic spikes are extreme and brief – auto-scaling is too slow; capacity must be pre-provisioned or absorbed through queuing. Seat-level contention increases super-linearly with concurrent buyers on popular events. Multi-event concurrency requires isolation – one popular event’s spike must not degrade the platform for others.
Partitioning strategy determines the system’s scaling ceiling – re-sharding after the fact is a major operational event. Adding nodes must increase capacity proportionally without redistribution storms. Write amplification from replication and compaction grows with scale – efficiency and scalability are directly coupled.
E – Efficiency
Memory versus precision is the fundamental trade-off – exact counting costs more than approximate (e.g., probabilistic structures). Hot-key mitigation (replication, local caching) has direct infrastructure cost. The cost of protection must remain a small fraction of the cost of the services being protected.
Index storage versus query speed trade-off defines infrastructure spend. Compute-heavy re-ranking versus aggressive caching represents the core efficiency tension. The cost of serving one search – indexing, retrieval, ranking, assembly – defines unit economics.
Inventory lock contention drives infrastructure cost during spikes – pessimistic locking is expensive but safe. Queueing infrastructure trades latency for stability, adding cost even when not at peak. Payment processing fees are fixed per transaction – optimizing conversion rates directly improves unit economics.
Storage amplification from LSM compaction is the hidden dominant cost. Write amplification from replication multiplies every write by the replication factor. Cost per request and cost per stored GB must both remain bounded as the cluster grows.
S – Security
Attack traffic mimics legitimate traffic – signature-based detection is insufficient. Identity spoofing (forged API keys, rotated IPs) defeats naive per-caller limits. Tenant isolation in multi-tenant limiters must prevent one caller from consuming another’s quota.
Scraping and data harvesting affect marketplace health beyond just data theft. Privacy controls determine what listing information is visible to whom and under what conditions. Fraudulent listings (fake properties, bait-and-switch pricing) require detection without blocking legitimate supply.
Bot protection and anti-scalping controls are table-stakes – without them, fairness is fictional. Payment security (PCI compliance, tokenization) raises the stakes of any breach. PII protection for buyer data must survive the full lifecycle: collection, storage, processing, and deletion.
Shared multi-tenant infrastructure magnifies the blast radius of any security breach. Access control boundaries between tenants must be enforced at the storage level, not just the application level. Encryption at rest and in transit is foundational – it cannot be deferred to “later.”
SCULPT ensures you build the right system by forcing problem framing before solutioning. A-PROMISES ensures the system survives reality by making trade-offs explicit rather than implicit. Together, they form a thinking framework or easy to remember mental model which can help with designing complex systems.
This post is about my management philosophy & default style (evolved over years & continues to evolve)
Management Philosophy & Evolution
My journey started with studying computer science for 6 years (2000-2006), 2 years in high school and 4 years in college, graduated from IIT Guwahati in computer science in 2006, after that have been working for last 20 years in the software industry, with first 10 years running startups (first one in advertising and second in communication domain), next 10 years working in fintech domain at larger organisations like Flipkart, Razorpay and Rippling.
The high level management philosophy I have followed in a nutshell is that, for effectively managing something (org / product / system / project / initiative / self etc.), the core competency needed for that something (can be tech skills / product capability / domain expertise / awareness) is primary and management skills or tactics are only supplemental. Management can’t operate in a vacuum and requires heavy contextualization to be effective. I have always focused more on learning from every experience (failures & successes) than to form a fixed lens or worldview on management.
Focus Dimensions / Axes
The following dimensions are basically the orthogonal axes for focus, which enables thinking of management as basically doing some level of trade-off on these 2 dimensions of focus.
Impact <> Excellence
This axis in simple terms is outcome focus. Impact being concrete / practical / short term / unsustainable focus, while Excellence being the aspirational / ideal / long term / sustainable focus. Excellence is divergence from reality towards ideal while impact brings convergence back to reality. Shifting focus from impact driven culture to excellence driven culture given move from smaller startup in advertising & communication to larger organisations with mission critical charter, heavily oriented towards fintech domain.
Impact-drivenculture - Prioritizes shipping features and outcomes that move business metrics and customer value. Shorter feedback loops, experiments, and clear outcome ownership are common. Excellence-drivenculture - Prioritizes craftsmanship, technical quality, maintainability, and best-practice engineering (tests, architecture, reliability). Focused engineering / product / operational excellence initiatives increases long-term velocity and product quality but sometimes in short term, can be mistaken for “engineering for its own sake.”
Excellence combined with Impact - It’s important to build resilient engineering practices (excellence) while keeping them tightly linked to business priorities (impact), few examples of losing track of this
Platform building is a good example of losing sight of impact & going into rabbit hole of excellence, sometimes diverging from reality and struggling for adoption later
Getting stuck in wrong trade-off discussion around quantity vs quality (mostly need to balance with hybrid approach) or breadth vs depth (balance required with hybrid approach), also sometimes one enables the other - high quantity of knowledge can enable quality, heavy depth on fundamentals will enable breadth of experience
Resilience is mainly used with reference to ability to recover from failures , basically the engineering practice which can recover when a person/process/product/system failure happens, one good example is practice of having checklist (design/development/deployment/operation) which works well well independent of the person, process, product or system. Another example is peer review (product spec review or tech spec review or code review, incident postmortem review) which prevents blind spots and improves rigor, much earlier in the lifecycle.
Excellence takes much more time than impact expectation in most cases and many times impatience gets many quick wins and smaller but visible impact, which makes people discard excellence as a theoretical and not valuable concept.
Execution <> Innovation
Execution being the progressive / realistic / immediate day to day focus, while Innovation being disruptive / unreal / beyond time horizon and sustainability aspect. Execution is the way to do things the proven way. Innovation is what breaks the existing cycle, out of box or out of cycle thinking is what results in exponential or step-function change.
Execution focused culture - incentivises & rewards high velocity work along with streamlined & predictable execution delivering consistent results which in turn reduces the risk of failing to deliver but increasing the risk of failing to innovate. Innovation driven culture focuses more on generating & pursuing new ideas while driving novel ways of working. Risk taking is appreciated instead of predictability & consistency.
Combining execution & innovation is challenging and only few people I have seen being successful at this, with clear understanding of when & what kind of innovation is feasible & will bring more value than simpler & incremental execution.
The management focus I have followed has significantly evolved over time, skewing more on Innovation > Execution, Impact > Excellence in the first ten years or my career running startups, while now after working in fintech industry for last ten years, the management focus shifted on the Execution > Innovation, Excellence > Impact, which also reflects the uncompromising need for excellence in finance domain due to higher demand of accuracy & reliability while bit less emphasis on innovation.
Underlying Principle
But the underlying principle for the above 2 dimensions is truth centricity or truth alignment, which is the most critical aspect I have kept in mind and it’s not another independent dimension.
Truth seeking - Information can mislead - very popular & common concept, evidence based approach to knowing, experience based learning, not taking words as wisdom & trust as the multiplier or signifier for truth. It basically means knowing the blindspots & pitfalls, having awareness of the unknown, while respecting & acknowledging ignorance. After relying on hearsay information once which then badly backfired, I have ever since ensured that I always have clear evidence in form of screenshot, dashboard, data analysis for statements made. This has acted as a forcing function for truth seeking.
Truth evangelizing - Be a friend not friendly - providing truthful feedback without sugar coating is more helpful than being friendly. A senior individual in general needs frank feedback but also a bit of debate to reflect, as a person with 10+ years experience will not change unless strong self reflection is triggered by something, to focus inward & put effort towards changing both behavioral & situational aspects.
Truth alignment - Truthful with reality - this is slightly different than seeking & evangelizing as even with sufficient evidence + feedback + reflection, there can still be misalignment of understanding of truth vs reality of truth, this divergence is mainly caused by delay in decision or lack of effort or out of control constraints, to converge truth in understanding to reality. This is more like zooming out to see the misalignment and taking steps to bring alignment.
Useful Tenets
Structured thinking is very important but equally important is to keep flexibility to go beyond the structure which has been put in place by yourself or others to not always think inside the box. An example is the “Why → What → How” framework, a simple hierarchy of decision-making
Why / Understanding — start with worldview, intentions, hypotheses. Only after clarifying “why,” define what you aim to achieve.
What / Objective & Key Results — once you know the why and outcome metrics, you set what needs to be done (goals, outputs). ‘
How / Implementation — only after “why” and “what” are clear, you decide the “how.” This makes your implementation more flexible and grounded.
This order helps to avoid tunnel vision & narrow focus on implementation without clear objective or purpose — a common trap in engineering work. But knowing the limitations of this framework (investment required should justify the ROI, this can’t reduce the risk of unknowns & uncertainty), along with the underlying assumptions (availability of knowledge & time to move up this hierarchy for decision making), is critical to avoid using it as hammer to nail every problem.
Embracing, Facilitating But Monitoring Change is an important way to learn, unlearn & relearn while also keeping a boundary around change.
Change has many layers / aspects and so do lack of change - these aspects tend to be different at different time horizons. Example - thinking nobody changes may be correct in the short run, but is wrong in the long time horizon as it takes a long time for people to change. Another example - Change in skill (upgrade or degrade) will sometimes take significant time but monitoring closely can easily show trends in a smaller time window to manage soon.
Change / Lack of Change has many dimensions - can (constraints), should (utility), will (motivation vs effort), want (awareness of impact) and when (timeline) are some important ones. Monitoring or observing changes with some detachment has helped in being aware & having less resistance to embrace change. Many times changes are incorrectly perceived due to false understanding of truth / higher invariant, which can enable discarding the changes in the lower plane, as being contextually not relevant in higher planes.
Change / Lack of change is not always controllable - as in the popular serenity prayer, wisdom is to know the difference between things that you can change and things you can’t change, along with having courage to change things you can while having acceptance for things you can’t change. One practical example in engineering is changing people’s behaviour is far more difficult than changing product / system behaviour. But if constraints make product / system change impractical / infeasible, it will be prudent to train people even with some difficulty.
Celebrating, Respecting, Encouraging Higher Goals is a critical part of building a happier & healthier individuals, teams & org.
Higher goals like diversity, meaning, growth need encouragement & celebration but without mandating it as to make it feel like a burden.
Diversity of thoughts, culture, background, practices, personalities, demographics are important, should be celebrated and respected as long as it’s in a contextually acceptable range for the team and organisation but not mandated. Merit and skill will always beat any mandate or criteria in long term when it comes to probability of success in the role, and the talent density being an important factor for success as a group, it’s important to not have mandates which affect talent density
Meaning brings satisfaction in a job, but it’s still a higher goal which should be pursued by individuals and not mandated as every thing can not have deep meaning but they will still provide heavy tactical utility. Sometimes encouraging and facilitating higher goals doesn’t work well when value is not understood, shown and appreciated, which can’t be solved with a mandate rather than a cultural shift.
Individual growth is a higher goal for people to pursue at their own pace, making it mandatory or expected, having an aggressive timeline results in many unwanted side-effects, people doing career growth hacking with promotion oriented projects, prioritising personal growth over team and organisation development. Have seen some examples - an engineer becoming EM to only realise they didn’t want the manager’s adhocness, schedule & pressure, another example of engineer pushing to get to next level but without looking for step function change in way of operating.
Higher goals along with talented people are generally very important to create teams working without too many rules and processes, just having talent density doesn’t necessarily bring discipline to succeed, it’s the higher goal which inspires people.
Thinking Tools - Have always been fascinated by thinking tools (particularly after reading “Intuition Pump & Other Thinking Tools”), as deep thinking is difficult & requires advanced tools.
Primary thinking tool like mental models like circle of core competence, falsability by experience, first principles thinking, higher order thinking, occam’s razor, ranson’s razor
Another very useful tool is developing intuition (heavily used by Andrew Ng in the ML specialization & Deep Learning specialization courses) and using intuition pumps (something which pumps intuition in desired direction).
Another one is using Nuance as the thinking tool, which can help in avoiding early conclusions & strong opinions, that are generally a way to disguise ignorance or may be sometimes skip deep thinking, also preventing tendencies for prescriptive thinking.
Default Management Style
I have been managing very diverse teams (by experience, talent, culture etc.) while working on varied challenges and the management style has changed / adjusted significantly depending on various scenarios. There is some benefit in general to have a default style of management to avoid daily surprises but it can soon become dogmatic, flexibility & adaptability has been a key behavioral trait to keep.
Default Style - The default style I follow is being supportive to the next set of leads whenever possible & feasible - supporting my team with a combination of inspiration + guidance + verification, while providing team with framework & mental model to be as much independent & autonomous as practically possible
Inspiration is more of long term strategic vision / mission / org / charter etc.
Guidance is more on tactical management challenges around operation / execution / org / talent / communication etc.
Verification is more for ensuring things don’t fall through cracks over time
While limiting the deeper daily intervention, only when the situation is in crisis or can get into crisis soon, and when the failure will be detrimental
Important Aspects - Few important aspects in managing larger teams with 2+ management layer requires
Growing senior talent - Creating opportunities for folks which are aligned with business while also stretching them to make step function changes in their learning & career is a critical way to retain senior talent while also helping them grow.
Risk management - creating next set of leaders & managers is generally not enough & there is need for strong succession plan, along with shadow / reverse shadow with them is critical to ensure continuity of context
Role model behaviour - displaying role model behaviour to solve problems which can be cleanly replicated - excellence initiatives, ticket commander process, design and post mortem reviews, domain expertise
Long term alignment - Aligning product charter / system design / org structure at larger org, team and individual level for long term success, without overlooking the current realities and constraints
Momentum driven execution - Generally momentum is what lifts-off large initiatives spanning teams and using momentum driven execution has helped in getting projects to a critical milestone - first & last mile delivery always need momentum.
Scenarios & Examples - Some examples using above management style during last few org experiences helped in ensuring
Stalled Projects - Have several examples of unblocking stalled projects across previous companies. Meta learning has been that momentum on those projects got lost, either due to past failure or the lost project driver, bringing back some excitement + getting a few smaller wins + making incremental progress helped in moving these along with establishing clear project driver for long run (not always project lead as most the stalled project has spanned across teams).
Turnaround & De-Risking Critical Path - Gone through a few examples of turning around areas (team + product + system) which have been struggling for sometime. Also, removing existential system / product / market / business risk (which can be due to various reasons). Meta learning has been to evaluate & understand situation with deeper thinking & planning on risk management + sustained execution, as these situation need multiple short term wins with strong focus on long running goal
Performance & Growth - Performance gaps are not always due to lack of intent or agency or even skill set, it’s due to lack of ability to bring impact or drive excellence. Generally people in tech companies work hard to get faster growth, but without strong sponsorship (sponsor is not just mentor or coach), it takes a lot more time. Meta learning has been that a combination of inspiration + guidance + verification is what helps senior ICs & managers grow.
Alignment & Process - Alignment & process reduces chaos and provides structure to operate. It doesn’t always directly cause impact or excellence, but without it have seen things getting very inconsistent. Meta learning has been that without thought through structure, freedom means innovation when no pressure but under pressure things become inconsistent and inefficient.
This post is about why nuanced, integrative thinking often produces better insight & more predictable outcomes than simpler prescriptive or one-sided thinking, with few examples for practical guidance around using Nuance as a thinking tool.
Background
Why Nuanced Thinking Often Beats Simple Prescriptions ?
Simple conclusions, prescriptions, or opinions have an obvious appeal — they’re faster to produce, easy to state, easy to remember, and easy to repeat. Nuanced thinking, by contrast, demands patience: it weighs tradeoffs, embraces complexity, and resists the illusion of certainty & clarity.
Generally reaching a simplified conclusion, advocating for a well defined prescription and forming a clear opinion is slightly easier than the nuanced approach, as it requires deeper understanding of the tradeoffs, which takes a lot more time and energy to think & master.
Taking a more nuanced approach which combines multiple frameworks (like in the example of breadth vs depth) will enable deeper understanding, reliable & stable decisions along with predictable outcomes.
Few Deep Dives
Skill & Learning: Breadth vs. Depth
Jack of all trades is master of none, but often better than a master of one.
The classic example is the breadth vs depth, which has been a constant debate over a long time and frameworks have skewed on either breadth or depth, more than often inclining towards the depth (given the distraction due to the internet, lack of depth is a big problem today). Even the popular saying Jack of all trades is master of none presents an incomplete picture compared to the original saying Jack of all trades is master of none, but often better than a master of one.
Depth-First (Specialist) Approach
Becoming world-class in a specific niche
Focused expertise in smaller context
Particular professions require it (e.g., neurosurgery, quantum physics)
Risk: Tunnel vision; may miss adjacent opportunities.
Breadth-First (Generalist) Approach
Diverse skills and perspectives
Flexible adaptability across wider context
Innovation through cross-domain synthesis
Risk: Lack of deep mastery; shallow outcomes.
Nuanced Thinking: “T-Shaped” or “I-Shaped” Thinking
A powerful integrated model — often used in design and management — is the T-shaped skill set:
Vertical stroke: Deep knowledge in at least one core area
Horizontal stroke: Broad familiarity across multiple domains
This lets a strategist or problem-solver apply deep expertise while connecting dots across fields.
Product & System: Velocity vs Quality
Simplistic Problem Prescription
“Move fast first, clean up later.”
This assumes following but all are false at scale
Cleanup is always affordable later
Technical debt interest is linear
Organizational context remains stable
Nuanced Thinking: Product-System Evolving View
Velocity and quality are temporally coupled, but mostly not oppositional. More nuanced strategy
Early phase:
Bias toward speed
But constrain blast radius with guardrails
Growth phase:
Reallocate capacity to foundational systems
Maturity:
Invest in reliability, tooling, and platformization
The mistake is not in moving fast — it’s moving fast without adequate architectural guardrails & forcing functions. Velocity vs quality is a false dichotomy, as without architectural quality it becomes very difficult to even achieve execution velocity.
Nuance As A Thinking Tool
Reaching a conclusion is relatively straightforward. Advocating a prescription is even easier. Forming and expressing an opinion is easiest of all.
What is genuinely difficult—and disproportionately valuable at senior levels is holding nuance in thinking. This has also become important in the AI/ML/LLM world, given the models today respond with so much confidence (even though on the surface, the response definitely shows high level of nuance with pros / cons, many dimensions covered in analysis, but it lacks self-doubt with carefully looking into the blindspots & pitfalls).
Nuanced thinking requires sustained engagement with tradeoffs, second-order effects, higher order abstractions, evolving constraints, and human systems. It demands time, energy, and a willingness to remain uncomfortable longer than most people prefer. As systems grow in scale—technical, organizational, and product-related—the difference becomes clear: most meaningful failures are not caused by lack of intelligence or effort, but by insufficient nuance applied too early.
Cognitive Comfort of Conclusions
Simple conclusions feel productive because they compress complexity into clean, portable statements:
Microservices scale better.
Optimize for velocity early.
Depth matters more than breadth.
Strong consistency is safer.
Each of these statements contains a meaningful insight but none of them is universally correct. Conclusions remove context while prescriptions flatten constraints and opinions replace inquiry with confidence. They are attractive because they reduce cognitive load and enable fast alignment—but they do so by discarding information that often matters later. At small scales or in controlled environments, this tradeoff is acceptable but at scale, it becomes dangerous.
Engineering - Not an Optimization Problem
At junior levels, engineering often feels like an optimization exercise: choose the best algorithm, the fastest database, the cleanest abstraction. At senior levels, this framing breaks down.
Engineering becomes the discipline of navigating tradeoff surfaces in evolving arenas, not maximizing single metrics. Every meaningful decision exists at the intersection of competing forces:
Latency trades off with cost.
Availability trades off with consistency.
Velocity trades off with system entropy.
Depth trades off with adaptability.
The core mistake is not choosing one side of a tradeoff. The mistake is pretending the tradeoff does not exist or assuming it will not matter later. Real systems are socio-technical systems. They include software, infrastructure, teams, incentives, users, and organizational dynamics. Optimizing aggressively along one axis almost always introduces instability elsewhere. This is why prescription-driven architectures often degrade over time—not because they were incorrect, but because they were too certain, too early, and too narrow.
Breadth vs Depth Is a Framing Error
The breadth-versus-depth debate has persisted for decades because it offers a simple story with clear sides. In an age of distraction, depth is framed as virtue. In fast-moving environments, breadth is framed as survival. The nuanced reality is less satisfying but more accurate:
Depth matters most at irreversibility points. Breadth matters most at integration points.
Data models, consistency guarantees, security boundaries, and core abstractions are expensive to change. These deserve depth, rigor, and restraint. APIs, workflows, cross-team interfaces, and product interactions demand breadth, contextual awareness, and synthesis across domains.
Senior engineers are not generalists or specialists in the traditional sense. They are selective specialists - deep where mistakes are costly, broad where coordination and alignment dominate. This is why the commonly quoted phrase is misleading in its shortened form. The original version matters more: A jack of all trades is master of none, but often better than a master of one.
Top-Down vs Bottom-Up Is About Timing, Not Ideology
Top-down and bottom-up approaches are often presented as opposing philosophies.
Top-down emphasizes clarity, direction, and alignment.
Bottom-up emphasizes discovery, feedback, and realism.
Both approaches fail when applied dogmatically. A purely top-down system risks detachment from reality. Decisions become elegant on paper but brittle in practice because they ignore operational friction and emergent behavior. A purely bottom-up system risks local optimization. Teams improve their own components while the overall system drifts, fragments, or loses coherence.
The nuanced approach recognizes that top-down and bottom-up are complementary, not competitive:
Top-down is essential early to establish constraints, boundaries, and intent.
Bottom-up is essential later to validate assumptions, surface edge cases, & adapt to reality.
In effective organizations, leadership sets direction top-down, while execution and learning flow bottom-up. The system remains aligned without becoming rigid.
Forward vs Backward Planning Is a Question of Uncertainty
Planning frameworks often polarize around two extremes. Forward planning starts from current capabilities and incrementally moves ahead. It is realistic, grounded, and low-risk—but can easily become incremental and reactive. Backward planning starts from a desired future state and works backward. It encourages bold thinking and long-term alignment—but can ignore present constraints and feasibility.
The nuanced approach depends on uncertainty and reversibility:
When uncertainty is high and reversibility is low, forward planning dominates. You move cautiously, learn quickly, and preserve optionality.
When the destination is clear and constraints are well understood, backward planning dominates. You align decisions toward a known outcome and avoid local detours.
Mature teams will often combine both, as hybrid approach prevents both aimless iteration & unrealistic grand designs
Backward planning helps to define long-term direction and architectural north stars
Forward planning helps to execute safely, iteratively, and within real constraints
Most Decisions Age & Need Rethinking
Architectural decisions rarely fail immediately. Instead, they age—sometimes gracefully, often poorly.
What works at 10 engineers starts to strain at 50.
What works for 1M users begins to fail at scale at 100M.
What works before compliance becomes fragile after regulation.
Prescriptive thinking implicitly assumes decisions are timeless. Nuanced thinking treats time as a first-class dimension.
A modular monolith is not an ideological stance; it is a temporal one. Microservices are not a badge of engineering maturity; they are a coordination strategy that only makes sense once certain organizational pressures exist. Good systems are not “right” in absolute terms. They are right for now, with an explicit understanding of when and why they will need to change.
Product & Engineering Failures Are Misalignment Failures
Many failures are labeled as engineering problems, but in practice, they are often product–engineering alignment failures.
Velocity without architectural guardrails compounds entropy.
Quality without urgency stalls relevance.
Feature delivery without system health creates fragile success.
The nuanced view rejects these as binary choices. Velocity and quality are not opposites; they are coupled across time. Moving fast early is often rational—provided the blast radius is constrained. Investing in foundations later is essential—provided the product has demonstrated real demand. The failure mode is not speed. It is speed without a plan for its consequences.
Predictability Comes From Explicit Tradeoffs
Systems become predictable not by eliminating uncertainty, but by making the assumptions explicit.
Nuanced thinking teams document:
What they are optimizing for today
What they are intentionally not optimizing for today
Which constraints dominate the current phase
When and why decisions should be revisited
This practice converts unexpected failures into anticipated ones, and catastrophic rewrites into controlled evolution. Over time, this discipline becomes a competitive advantage, silence is not neutrality but is hidden technical and organizational debt.
The Real Marker of Thinking Maturity
Nuanced thinking is cognitively expensive. It resists slogans and soundbites. It does not fit neatly into decks or one-line principles. It often sounds conditional, cautious, and incomplete—especially when compared to confident prescriptions. But at senior levels, conditionality is not weakness, it is an evidence of understanding.
Strong engineers defend solutions.
Senior engineers explain tradeoffs.
Principal engineers design for change.
The most reliable signal of thinking maturity is not the number of systems someone has built or the tools they know. It is how they reason about questions such as:
What depends on this decision?
What breaks if our assumptions are wrong?
What are we consciously sacrificing?
How does this decision age over time?
If an answer sounds overly simple, it is often shallow. If it sounds more nuanced, it is usually grounded in lived experience. The internet rewards opinions and certainty but organizations survive on nuance.
As systems grow larger, slower, and more interconnected, the cost of premature certainty grows with them. The role of senior engineers & product leaders is not to eliminate complexity, but to engage with it deliberately and transparently. Nuanced thinking is not indecision instead it is respect for reality.
System design and product development are not about finding the “right” answers — they are about making context-aware, time-sensitive tradeoffs explicit.
Nuanced thinking:
Replaces ideology with adaptability
Trades speed of conclusion for durability of outcome
Produces systems that evolve instead of collapse
In real life scenarios, clarity is not the absence of complexity — it is many times, slightly deeper level of thinking around complexity.
This is a post on I-Shaped learning framework to build expertise
Overview
Generally for building technical & engineering expertise, the learning framework which has worked well is something like an I-Shaped Learning where there are three important components of the learning plan which are explained in the diagram below.
There is a lot of debate going on with regards to breadth focus vs depth focus. Even the popular saying “Jack of all trades is a master of none” is misrepresented today as an insult to people who are focusing on the breadth while ignoring the depth but the original full quote “Jack of all trades is a master of none, but often times better than master of one” was in fact a complement.
General guidance for the plan would be to spend equal time on each of the three components (minimum 4 weeks each) in the first iteration & repeat again for deeper learning. The plan is basically a checklist, create a copy & update each of the checklist item with specific details, artifacts like docs, mind-maps etc and individual learning.
Breadth On Fundamentals
Learning a wide range of fundamentals (computer science, coding, design & language) is very important to build mental muscle to understand different nuances & comfortably handle technical complexity as well as building a good grip on systems.
CS Fundamentals
This should be covered by any CS fundamentals MOOC course in references, follow one course & complete it, instead of spreading thin across many information sources.
Data Structures
Basic Data Structures
Understanding & practicing problem solving using the basic data structures - arrays, linked lists (singly & doubly), lists, stack/queues, min/max heaps, maps, trees. Also various data structure considerations - space, time complexity (read/write).
Advanced Data Structures
Understanding & practicing problem solving using some of the advanced data structures considerations (memory hierarchy with caches, hashing techniques, immutability, large data sets) and examples (priority queues, binary trees, bloom filters)
Understanding & knowledge of a couple of advanced algorithms from any domain like - parallel (matrix multiplication), streaming (count-min sketch), randomized algorithms (quicksort), string (suffix trees), graph (DFS, BFS), mathematical (linear programming).
Coding Fundamentals
The clean code book & the examples link in references can be a good start as it covers many of these things.
Code Design
Code Constructs
In-depth understanding of common code constructs (variable/constant, conditions, loops, functions, type/class, try/catch, thread safety, annotation) and knowledge of advanced constructs & concepts (macros, currying, trait/aspect, symbolic tree)
Code Structuring
Learn various code structuring mechanisms (modular decoupled structure, convention based structure, domain driven design based structure, tech vs functional oriented, frontend/backend structure, framework vs library structure) & list examples for each.
Coding Practices
Coding Best Practices
Learn & list down coding best practices - language independent like general (naming, readability, indentation etc), design (low coupling, don’t repeat yourself) & language specific like syntax (standard linting, using obvious not obscure constructs, nuances of constructs), semantics (exception handling, concurrency, built-in types behavior).
Code Review Best Practices
Learn & list down code review best practices - code review checklist (readability, security, structuring, test coverage, reusability), code review metrics (inspection rate, defect rate, defect density), code review automation (danger.js), code review diligence (400 lines at a time, nitpicks %), code review etiquettes (suggestion instead of command, conversation instead of fault finding)
Design Fundamentals
Design Patterns
Solid Principles & OOP Design Principles
Go through & practice some of the important design patterns like observer, strategy, adapter, facade by implementing them. Common design principles like SOLID, OOP (composition over inheritance, container structure using core + extensions / modules / plugins - for inversion of control & dependency injection)
Distributed System Patterns
Go through and learn various distributed design patterns like single node patterns (side-car pattern, adapter, ambassador), multi-node patterns (discovery, cluster management patterns - consensus algos, leader/master election, data/control plane), batch computational patterns (work queues, event based processing, coordinated workflows), distributed transactionality patterns (2-phase commit, saga pattern etc.)
Design Anti-Patterns
Code & Design Anti-Patterns
Learn some of the common coding anti-patterns (spaghetti code, god class, cyclic dependencies, copy/paste, golden hammer, dead code, scattered code, boat anchor) and code smells (duplicate code, large functions, lazy/large class, mysterious naming, unsafe type handling, side-effects)
Distributed System Anti-Patterns
Learn some of the common distributed system anti-patterns - microservice anti-patterns (distributed monolith, shared database, dependency disorder, entangled data, improper versioning, missing api-gateway) & list down reasons why these result in bad design.
Language Fundamentals
Language Independent
Programming Languages Landscape
Look at various programming language families (procedural. object oriented, declarative, functional, logic), operating model (interpreted, compiled), abstraction level from machine to humans (machine, assembly, high level), origin (academy, industry)
Programming Languages History
Many of the languages have evolution paths where sometimes in the new language, fundamental changes are introduced while other times its only incremental new constructs. Go through a couple of these like c -> c++, java -> scala, erlang -> elixir.
Language Specific
Constructs & Language Design
Language constructs starting from syntax to semantics, then looking at the overall language design. Constructs for different programming paradigms - declarative (macros, annotations), procedural (first order functions, loops, conditions), oop (type, inheritance, polymorphism, generics, reflection), functional programming (closure, higher order functions, pattern matching, list comprehensions) etc. Do this for any one language.
Language Evolution & Philosophy
Language evolution and philosophy are important to know and understand, this builds the context in which programming language has been developed. Most being open-source helps in looking at the evolution of the language & learning.
Compiler & Virtual Machine Internals
The way language and various constructs operate or are implemented in the VM, this gives a good view of the VM for doing tuning, optimisation and knowing internals like scheduling, memory management helps in debugging & troubleshooting issues.
Depth On Single Tech Stack
Important thing to keep in mind for this section is to reduce context switching & have deeper thinking to understand the journey of a tech stack well, so that the learnings here can be extrapolated quickly for any tech stack, whenever required on demand.
Tech Stack
Stack Selection
Select Tech Stack
Based on interest, select one of tech stack for deep dive (like data stack - any sql or nosql data stores or messaging stack - kafka, rabbitmq or functional stack - elasticsearch, neo4j or infra stack - docker container, kubernetes)
Tech Stack Mind-map
Mind-map for covering the breadth of the tech stack - pros/cons, high level design, when to use this tech stack, comparative analysis with competition, use-case mapping (popular use cases with understanding of why this tech stack was preferred)
High Level Design
Component / Block Diagram
Create the component or block diagram based on the HLD understanding of tech stack, iterate over it couple of times and then compare with the existing component or block diagram from tech stack developers
Data & System Architecture
Create the data & system architecture of the tech stack based on the HLD understanding of tech stack, iterate over it couple of times and then compare with the existing data & system architecture diagram from tech stack developers
Deep Dive
Low Level Design
Schema & API
Go through & list down the data schema (for meta, master & transaction data models) and various APIs (type - sync/async, protocol - rest/grpc, format - xml/json, security - authn/authz, contract - sla/limits, robustness - idempotency/degradation)
Tech Stack Components
Go through & list down the important components like language, base libraries (like lucene for Elasticsearch), abstraction layers - data, logic & api layer, underlying storage mechanism, concurrent processing mechanism (threading vs lightweight processes)
Code Level Design
Data Structures & Algorithms
Go through & list down the important DS/Algo used in the tech stack, need & rationale behind using those, what optimisation (space or time or both) these DS/Algo bring, review the space/time complexity, are there better alternatives & why.
Data/Compute, Code, Read/Write Flows
Go through & list down the important flows in the tech stack - from different point of views - data & compute, read & write flow, code flow. Create the flow diagram for the listed flows along with their inter-relationships like cross-dependencies, pipelines etc.
Evolution
Design Tradeoffs
Fundamental Resource Tradeoffs
Go through and list down the fundamental resource tradeoffs (compute, storage, memory, network, time) that are applicable to the tech stack, why these tradeoffs are important for the success of the tech stack
Distributed System Tradeoffs
Go through and list down the distributed system tradeoffs (consistency - serializability & linearizability, availability, partition tolerance) that are applicable to the tech stack, why these tradeoffs are important for the success of the tech stack.
Decision Log
Critical Design Decisions
Go through & list down the critical design & architecture decisions from inception, look at the anatomy of each of these decisions (3 fundamental parts for each decision - problem - approaches - solution) and the retrospective of decision - impact, pitfalls etc
Important Design Decisions
Go through & list down the important (non-critical) design & architecture decisions, look at the anatomy of each of these decisions (3 fundamental parts for each decision - problem - approaches - solution) and the retrospective of decision - impact, pitfalls etc
Breadth On Tech Stacks
This section is the last and open-ended, it is more like understanding the landscape of tech stacks based on various needs & use cases, mainly to be able to judiciously choose the appropriate tech stack whenever needed based on various parameters.
Considerations
Tech Stack
General
Create mind-map for the important things to consider when evaluating any tech stack - pros/cons, high level design, when to use which tech stack, comparative analysis, use-case mapping, functional/non-functional & ecosystem related evaluation criteria
Non-Functional
Go through & list down the non-functional considerations (security, robustness, stability, resilience, scalability, performance) which are important for selecting any tech stack for a given problem, why they are important & how to measure each of these considerations.
Ecosystem
Support, Community & Management
Go through & list down the ecosystem considerations like support (sponsors, core contributor activity etc), community (size, involvement) & management (managed service, paid support) which are critical for operability & sustainability of tech stack.
Benchmark & Independent Evaluations
Go through & list down the various benchmark & independent evaluations to be reviewed to be able to take more data driven & well researched decisions. For example - https://jepsen.io/ is the de-facto standard for distributed system evaluation.
Landscape
Data Stores & Messaging
SQL & NoSQL Data Stores
Go through different sql databases (mysql, mssql, pgsql, oracle) and nosql datastores like key-value stores (redis, aerospike), columnar stores (cassandra), document stores (mongodb, couchdb), graph stores (neo4j, dgraph), search store (elasticsearch, solr)
Generic vs Specialized Data Stores
Look at the datastores from generic vs specialized functionality point of view - generic (sql db, in-memory, key-value, columnar, document) or a bit more specialized (graph, search, time-series, analytical). Mind-map for considerations for a few categories.
Messaging Frameworks
Look at the popular messaging frameworks (like kafka, pulsar, rabbitmq, activemq), messaging considerations like functional (delivery guarantees), performance (throughput, latency), consumption model (pull, push), storage model (log, index)
Processing & Application
Stream & Batch Data Processing
Go through & list down the open-source stream & batch data processing frameworks like storm, spark, flume, flink, skoop) & commercially available (redshift, athena, snowflake, big-query, synapse)
Application Frameworks & Libraries
Go through & list down the application framework & libraries which are relevant for current work - backend(django, flask for python, gin, gorm for go), frontend (react, vue, angular), other framework & libraries (grpc, graphql, rule engine, workflow engine)
As the organization scales & in general also, the biggest challenge is that of decentralized decision making, these are some thoughts on how to enable this. It can also encourage deeper participation, experimentation, innovation and keeping the team driven.
Problem
The biggest challenge in the growing organization is around decision making, how to enable decentralization of decision making. When the organization is small, context is limited and most of the time centralized decision is what works well and not much alignment needed, sometimes the divergent views are not present while other times time is limited.
But as the things scale, context increases & decision making becomes more complex as well as nuanced. Teams need a framework which can enable them to take decisions without being too dependent on the leadership or experts.
Solution
Transitioning from How to What to Why or Doing to Knowing to Understanding becomes a stepping stone in moving from centralized decision making to decentralized decision making allowing people to choose what based on why and how based on what. The why (understanding) inspires & motivates the what while the what (knowledge) guides & aligns the how (doing).
The difficulty comes as there is no standard way to define these and even though the idea of moving from how to what to why seems good on paper but operationalizing it is not easy. Below is the framework to define & evolve the How to What to Why over time.
Framework
Core flows in working through anything can be done at three levels - how, what & why. The decision making is also required at each level & the most important thing for decisions in the fast changing world is the flexibility & agility to change the decision in response to new information or dynamic circumstances, for this we need to move to higher order thinking by pushing the decision to the next level. Basically when the focus is shifted to “what”, “how” becomes flexible & open-ended, similarly shifting focus to “why” makes the “what” flexible.
How / Doing / (Solutioning + Execution + Operation)
This is the implementation or in general terms tactical level which covers end to end roadmap to get somewhere by doing. It involves problem solving which itself can be divided into 3 phases - solutioning (problem definition -> exploring approaches -> finalizing solution), execution (planning, implementing & delivery), operations (production support, maintenance & evolution). This is the most important level to bring anything to life, but this level is a lot more focused on doing & lacks seeing the bigger picture of whether something is relevant for a larger goal or not.
The decisions here tend to be much more tactical in nature as getting something done is more important than to introspect/retrospect/prospect on whether it is good in the long term or not, whether it moves us towards the larger goal or not. Also, this level is more input or effort oriented instead of outcome oriented which means focus will be to think of how to do something rather than what to do, which also makes it less future proof as even if the result or outcome is not getting achieved, the decision need not be changed.
Defining what has a lot to do with knowing deeply about the problem which is critical to define the success metrics for any solution. Once the success metrics is in place, what needs to be done becomes clear but the objective along with key results quantifying & slicing the what based on time (different quarters) & space (various teams). Decisions to do “what” are completely focused on outcome & will help in making the “how” flexible as it doesn’t matter which solution brings the outcome as far as it is achieved.
Why is the highest level in the framework with focus on the reason, intention & rationale behind doing something. This is the level where civilisational & cultural lens matters, based on the environment & upbringing of the person, team & organization, the worldview will be formed which will then drive the hypothesis & experiments to make decisions based on the “why”.
WorldView - This is generally not discussed in detail and also lot of times abstract & not defined concretely as its subconsciously built in form of learnings from environment.
Hypothesis & Experiments - The hypothesis helps in making some prediction based on the world view & doing experiments to evolve the hypothesis.
General Concepts Around Decisioning
Problem vs Solution Focus
The problem & solution focus many times becomes important to be flexible towards solutions and not become rigid with a solution. It will also enable us to move from deterministic thinking to hypothesis thinking (where solution is seeked using hypothesis + experiment).
Deterministic vs Probabilistic (Hypothesis) Thinking
The hypothesis approach towards defining problem & solution is by default adaptive while a more deterministic approach might be appropriate for situations where being right is critical (even if it means to delay decision & wait for sufficient information). Probabilistic thinking enables incremental decision making by refining & evolving the hypothesis with more experiments (gathering relevant information).
Assumption Blinds vs Hypothesis Guides
Assumption is basically an implicit unknown & unproven point taken as truth while hypothesis makes that unknown explicit which is important to understand the gaps that can be there in the decision being made due to imperfect knowledge & understanding of the world around us. Sometimes facing ignorance explicitly is a lot better than implicitly claiming knowledge, which is probably the reason for many decisions being incorrect & that coming as surprise too.
Progress vs Perfection (Incremental Thinking)
In most of the decisioning cases, progressive decisions are better than aiming for perfect decisions, incremental thinking helps in evolving decisions which is more future proof.
Acknowledging Ignorance vs Claiming Knowledge
Focusing on ignorance & acknowledging it will result in seeking more knowledge & understanding of the world around us needed to make better decisions while claiming knowledge when its not there, will only result in decisions with of lot of faulty assumptions that can not only make the decision wrong but also result in incorrect learnings from those decisions.
Journey vs Destination vs Intention
The decisioning framework of how -> what -> why is also closely related to the thought process of moving from journey (process of getting somewhere) -> destination (knowing somewhere to go) -> intention (reason to be thinking of a destination). Generally people who understand intention will not be fixated on a destination and definitely will not be bothered to take a journey to any destination based on the larger intention.
Making Right Decision vs Making Decision Right
Most of the time the focus is on making the right decision which pushes us to think a lot, gather as much information as possible, create mental models & decisioning frameworks. But we need to give a lot more importance on how to make the decision right once that decision is made as it’s not always possible to see the correctness of a decision in the short run & many times as it takes a long time to see the truth of the decision. The approach to decision making should involve a good amount of effort & thinking on both aspects - what will be the right decision & what will it take to make the decision right.
Will be writing another post soon to look at some of the examples for using this framework & the learnings from that, it may not be the best framework but can help in steering to the shore.