Sanskrit Varnamala
06 Jul 2020- संस्कृत वर्णमाला (Sanskrit Varnamala)
- लघु पृष्ठभूमि (Little Background - लिटिल बैग्राउंड)
- संस्कृत संख्या (Sanskrit Sankhya)
- संस्कृत पंचांग (Sanskrit Panchang)
- संस्कृत वर्णमाला (Sanskrit Varnamala)
- सारांश (Summary - संमरी)
संस्कृत वर्णमाला (Sanskrit Varnamala)
This is the first essay in the series on the value (usefulness and uniqueness both) of the Sanskrit Varnamala which needs to be adopted to better enrich the awareness of our speech mechanism and also make it easier to pronounce words accurately in any language. The multiple pronunciation in English or any European language is not just a problem of accent of people (which is the popular belief), its more of the problem of the language design which creates the multiple pronunciations issue.
लघु पृष्ठभूमि (Little Background - लिटिल बैग्राउंड)
The sanskrit varnamala is the most elaborate and well organised alphabet system in all human languages and we can easily see that by just looking at the following few things
-
All the Roman/Latin alphabet based languages are not spoken the same way as they are written - This is mainly due to the lack of representation of all the sounds in the alphabet which means the divergence between the written and spoken language, this problem is being attempted to be solved using IPA which is again aligned with Latin alphabet and trying to solve only by borrowing symbolism from different other languages. From my experience its much more difficult to remember and use IPA whenever learning a language, the symbolism used is so close to each other that its easy to get confused. There are other subtle aspects or problems with IPA which are very well handled in Sanskrit Varnamala, will write about those in another blog post. This divergence between spoken and written is not at all there in Sanskrit and almost all of the Indian languages.
-
The Sanskrit varnamala and its different symbolism is very closely aligned with human speech apparatus (vocal tract) which means any sound produced by human can be easily represented using the Sanskrit alphabet independent of the language which associates meaning to the sound and its easy to visualise, to become aware of the configuration of the speech apparatus for producing that sound which means that if you learn the varnamala, you can produce the sounds even if the meaning is not understood which is important to initially learn to speak a language.
-
The organisation of the Sanskrit varnamala is done with a lot of thought not just to align the sounds closely to the configuration of the vocal tract but also how it makes sense when sounds are sequenced together in speech (not the sandhi rules which is slightly different phenomenon concerning how sounds change when combined/spoken together without gap) which means a way of writing not just individual letters of the alphabet but also how they work when combined together which is very difficult to do in IPA today. Representing any Indian language writing in IPA is not just difficult but not possible with current ways, people use IPA as an approximation today.
संस्कृत संख्या (Sanskrit Sankhya)
The numerals used in mathematics today are generally called “Arabic Numerals” which is not correct, just a simple logic of why it has not been developed in Arabic and is actually copied from Sanskrit is the fact that the Arabic language is written right to left while all the mathematics based on the modern numerals is left to right (simple google search). There are other concrete evidence for showing the flow of numerals along with concepts of zero, place value, negative numbers and decimal system from India to Middle East and then to Europe like the book Hisab Al Hind and multiple other evidences of problems faced before discarding the existing Roman & Greek numerals. An obvious question arises is that if the current numerals used in mathematics is not Arabic, then was there “Arabic Numerals” similar to the Roman and Greek numerals and the answer is yes, it can be seen in the writings before the transmission of sanskrit sankhya. The Arabic, Persian & Hebrew numerals were mostly derived from the Egyptian numerals which had a similar system like Roman/Greek system but was written from right to left.
The Sanskrit Sankhya is adopted by most in mathematics across the board now while the Roman & Greek numerals are still being used for bullet points, variables etc but not for calculations any more. This was not done due to power of sword or gun, it was only due to the efficiency of doing calculations with these methods and its very clear that the numerals as symbols themselves don’t have much role in bringing the efficiency. It was the concept of zero, negative numbers, place value system along with decimal point system which made the symbols so much powerful to improve calculation efficiency, the computers today can easily do these calculations with any symbols which means that when Sanskrit Sankhya were adopted it was not just the symbolism that was changed but the very way of doing calculation got changed. Its extremely important to keep this distinction between symbolism and methodology which is much deeper aspect, the reason for emphasising on this difference is that all the Indian languages may or may not have same symbols for the numerals but had the same methodology for calculations which means this knowledge was well understood in Indian subcontinent to be able to use the methodology even without the same symbols.
The problem in lot of cases with adoption of Sanskrit Sankhya without proper understanding and source attribution was that it took a very long time (nearly 700 years) before it was accepted as the standard way of doing calculations and then it didn’t evolve for quite some time as it is still today only being accepted hesitantly as Indian in origin. For understanding the difficulties faced for accepting the new calculation methodology are explained in detail by professor C.K Raju in the lecture on origins of calculus, there are lot of other interesting things to be talked about the Sanskrit Sankhya and to understand these directly from source, which is basically Sanskrit texts, can provide a lot of gems similar to zero, negative numbers, place value and decimal point system. Additionally the lectures on evolution of ganita in India by M.D Srinivas and golden age of ganita in India by K. Ramasubramanian gives a lot of insight inside how the ganita was developed in India.
There is definitely lot of scope of finding many insightful things embedded in the Sanskrit literature and more importantly how these methods evolved to better understand the reasons for choosing 10 as the base system instead of 12 (which was always more popular among other civilisations). Similarly how did the decimal point based system for representing fractions evolved and how its efficient than the numerator/denominator based representation of fractions. The more advanced topics of irrational numbers and numerical methods for calculating sine differences etc are to be explored and understood in the light of the well thought through fundamental principles of decimal and place value system along with infinitesimal which is close to extensions of the concept of zero.
संस्कृत पंचांग (Sanskrit Panchang)
The modern calendar is something which is extremely flawed and is very interesting to look at from historical point of view, there are so many things copied in the Gregorian calendar for reforming the Julian calendar. The wikipedia article on history of calendars says that the Gregorian calendar introduced in 1582 is the de facto calendar for secular purposes, which is not correct as its still deeply linked with Christianity. Anyways its not important what is being used now, the more important thing is that can Sanskrit Panchang (which should not be called Hindu Calendar as its not same as the other calendars and is based on completely different set of concepts) help in improving time keeping and associated tasks compared to the current calendar. The comparison of the Gregorian Calendar and Sanskrit Panchang is very nicely explained in detail in the video “A tale of two calendars” by C.K Raju and there is need to evaluate the efficiency of the two for time keeping.
The lack of negative numbers in Europe has created instead of one timeline, the two timelines of AD-BC (AD going forward and BC going backward from the arbitrary point of origin which actually is based on religious belief of Christianity) and each having only positive numbers used due to either understanding of negative number completely missing or due to fear of how can date be negative. Again the negative numbers currently are attributed to Chinese Han Dynasty while only mentioning the use of negative numbers by Brahmagupta in 7th Century. The negative numbers were actually in use much before Brahmagupta & Bhaskara in the accounting principles of the Kautilya Arthasastra which was much before the 300 BC, this paper also shows the lack of acceptance of negative numbers impact on the accounting which then lead to delay in credit/debit and asset/liability concepts better represented mathematically using positive/negative numbers.
संस्कृत वर्णमाला (Sanskrit Varnamala)
Now after looking at the above two examples of sanskrit sankhya and the sanskrit panchang, its time to discuss the varnamala and why it makes sense to drop Roman/Latin alphabets which are not correct enough (for many sounds) and not very efficient to represent the human speech along with a lot of associated sound phenomena. The reason for not using the term “sanskrit alphabet” and instead keeping it as sanskrit varnamala is to avoid missing the uniquely different methodology being used in sanskrit varnamala which is totally different from any other alphabet.
Just to see the way sanskrit varnamala enables better representation of sounds, correct pronunciation of both individual as well as sequenced, combined sounds but also efficient way of being aware of vocal tract configuration when making those sounds, few of these videos provide insights on this 1, 2 and 3. The common problem of accent in English speaking (almost every community in the world has their own English accent) is due to this problem of ambiguous pronunciation and a lot of transliteration of Indian language words and names to English suffer with this ambiguity, just to give an example Indian names written is English are almost always pronounced incorrectly by different cultures (for example my name written as Akhil in Latin alphabet is pronounced एैकिल in America while its pronounced अकिल in Middle East and अखिलअ in South India, but the correct pronunciation is actually अखिल which is the only word out of four that has some meaning in Hindi/Sanskrit).
Actually Sanskrit has so many elaborate concepts (and the associated symbols too) which are present in most other Indian languages but are largely obscured, simplified or not understood at all. Will go through some of these here and why it is very important to adopt the methodology of Sanskrit varnamala along with the symbolisms to make it efficient to learn a language and precisely produce sounds, no divergence between written and spoken. Here again to point out that all Indian languages uses the same methodology used in Sanskrit but different symbolism. This distinction between methodology and symbolism actually can make it much more easier to learn to speak and listen to any Indian language if you know Sanskrit (although reading/writing will require some practice with the language specific symbols).
Another example of distinction between methodology and symbolism/representation can be seen in programming languages too like the concept of type which is represented differently in different languages like C, C++, Java etc as explained in this video on evolution & essence of C++ language but is essentially adopted from Simula which allowed for defining custom types. And although in programming languages there are lot of major differences in the way “type” is defined in each programming language, this is actually not the case with Sanskrit and Indian languages (which mostly has simplified or discarded some of the concepts in Sanskrit but haven’t done major conceptual variations).
Here are few of the concepts which look simple on the surface and can be misunderstood to be variation of similar concept in other languages but are very distinct concepts in Sanskrit
-
The first is the method of organising sounds in Sanskrit is by the place of stop put by the tongue to block the air (or articulation by stopping the air). This is also extended for vowels and semi-vowels which don’t block the air but modulates the way air is pushed out of mouth. This method is understood as just a way to divide the sounds but it has quite a few implications like the following:
-
This above categorisation impacts the way the अनुस्वर is to be interpreted, the pronunciation of अनुस्वर depends on the letter coming next to it like अंत (pronounced as अन्त) is different from the अंडा (pronounced as अण्डा), this is a concept of contextual substitution of nasal sound based on place where the अनुस्वर is placed. This contextual phenomena can be easily understood if seen with reference to the configuration of the vocal tract which then makes the contextual substitution of nasal sound There are some of things defined in phonetics like the concept of allophone which is thought to be similar but conceptually it is very different as its only talking about having different signs for two sounds or not in a language which doesn’t have any relation to context of vocal tract. Basically the above categorisation provides the context of one important aspect of vocal tract which is the tongue position.
-
This above categorisation is also extensively used to define the sandhi rules in पाणिनि व्याकरण (which are not some arbitrary rules defined in a language), it closely follows the vocal tract configuration and the approximation of sound representation to reproduce the same vocal tract configuration such that even with dimensional variations of the vocal tract, the person will still produce the same sound when reading this representation. The design of the categorisation is such that if its understood that the categories are representing the position of tongue in the vocal tract configuration, it will start making sense how the other modifications of vocal tract will work for each category.
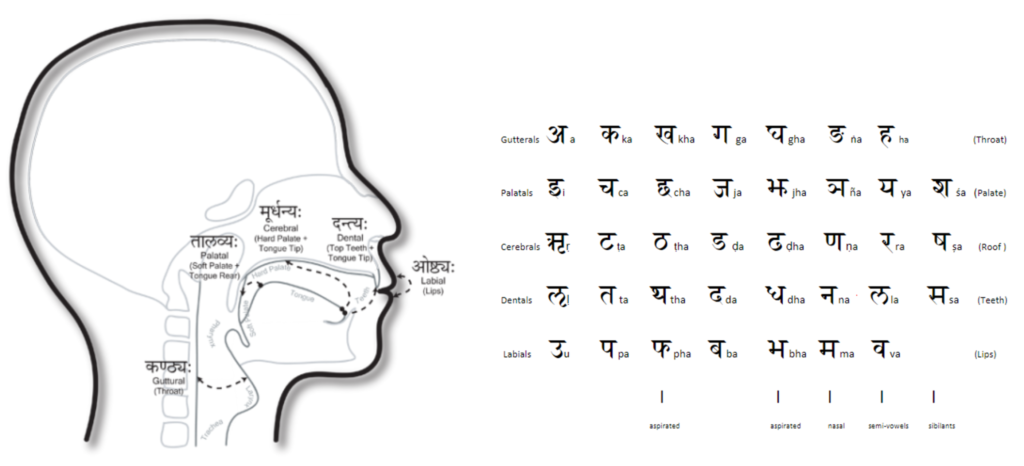
-
-
This concept is not commonly present outside of Sanskrit (even not in the other Indian languages) - variation produced due to place of origin of the sound (उत्पत्तिस्थानानी), this is explained in detail in the Panini Ashtadhyayi course by Sri NCT Acharya. On a very high level concept is that the place of origin will determine the slight variation in sound which is basically independent of the person or intention but has associated semantics.
-
This variation is different from accent which is more due to the explicit emphasis put on sounds or combination of sounds, either due to emotion, surrounding or any other intention. Every language will have some of this, for sanskrit there is some information which can be read here
-
This is also different from the concept of intonation which is the rise and fall of the pitch and is generally associated with the music or making speech musical. Pitch and tone are both sound focused measurement and are defined based on the perception of the ear for the sound and not specifically linked or studied with respect to the origin of the sound.
-
-
The depth in which varnamala is studied in Sanskrit can be easily seen as the first of the six vedangas is called शिक्षा (siksha) which deals with the understanding of the way sounds are produced using the speech mechanism with four dimensions - effort (prayatna), place (sthana), force (bala) and duration (kala). Here are some important points highlighting the depth of varnamala
-
The use of varnamala is not just the basis for Bhasha but is also done extensively in defining underlying principles for lot of other vedgangas like महेश्वर सूत्राणि in vyakarna and कटपयादि संख्या in ganita which is part of jyotish
-
The depth goes even further due to the much elaborate thought process around four energy levels or phases of sound - Para, Pashyanti, Madhyama and Vaikhari ( परा , पश्यंती , मध्यमा , वैखरी ) which is still an unexplored topic for me and will need lot of understanding along with reading. But mostly the first three phases are not even expressed and requires a person to be in much deeper state to realise those.
-
The concept of root sounds (dhatu) conveying meaning of several related ideas, which are themselves originated from seed (bija) sounds, this enables much faster learning of language without having to remember all of the vocabulary but rather learning to arrange the words according to the widely applicable rules, this is the most powerful attribute of sanskrit, will write another post with details on the this, for some initial reading, this is a good article - root meaning to begin with.
-
-
The IPA representation is so bad to even read and understand, this is the primary reason still today its not being used at all except when providing pronunciation guidance for words (especially for the languages which diverges in speech and writing). Its extremely complex and has mostly adopted organisation of sounds (and corresponding symbols) over time through different language inputs which is going to make it unusable for practical human purposes even in future. Few important things about IPA needs to be highlighted here
-
Looking at the evolution of IPA from 1888 to present, it cannot be easily seen the influences of Sanskrit at all from the wikipedia article, but if you dig a little into the origins of the Romic Alphabet proposed by Henry Sweet as a alphabet reform (through the 1877 book, A handbook of phonetics which was done after (you should see the similarity here with the Gregorian reform for calendar done in 1582 using unknown sources) contact with India. Another reference book to look at the history of linguistics (and phonetics) in west is the book “Philology: The Forgotten Origins Of Modern Humanities” by James Turner, which says linguistics became university discipline in decade after 1850 attributing the beginning of philology to William Dwight Whitney and Max Muller (both were professors of Sanskrit), there is also mention of Henry Sweet who was head of Philological Society as the man who taught Europe phonetics.
-
The spelling reform which was started in 1850 due to the problem of multiple representation of spoken word which makes the spelling ambiguous, it basically arises from the mismatch between the way English is written and spoken, and this reform aimed basically to bring some commonality in the way spelling for word is to be determined, some more details can be found in the book by Alexander John Ellis called “A Plea For Phonotypy and Phonography”. The problem of ambiguous spelling in English was made popular by spelling the “Fish” as “Ghoti” which is valid spelling as “gh” is pronounced as in enough (ईनफ़) or tough (टफ़), “o” is pronounced as in women (विमन) and “ti” is pronounced as in nation (नेशन) or caution (कौशन). Now fish written in devanagari like फ़िश will have only one pronunciation without any ambiguity, in Sanskrit the way sounds are represented is mostly unambiguous and obvious, while in some cases it might not be immediately clear without deeper understanding due to the contextual pronunciation of some of the decorators like ं which basically is to add the nasal effect and its not always to be pronounced न in all the cases.
-
सारांश (Summary - संमरी)
The Sanskrit language based culture is really interesting and has so many concepts which makes learning easy and fun, particularly Sanskrit varnamala solves following problems in language learning (will be building a language learning course in near future)
-
No divergence between speech and writing - This is already discussed widely, its one of the biggest challenge in language learning and can be easily removed by just adopting right approach towards language design, in case of natural languages the evolution is not completely organised, which means the language becomes ambiguous over time but the sounds at least can be better represented in writing as the speech apparatus of humans haven’t changed in long time.
-
Different pronunciations in same language - If you watch any American or British movie for the first time, even though the language is English, the pronunciation makes it very difficult to understand and comprehend. I think similar problem will occur with different Spanish speaking countries. It is slightly present in the Indian languages too due to the simplified writing which results in different pronunciations, if all the symbols are utilised to give representation of exact sound, it will be easier to reproduce the same sound again. This doesn’t mean reduction in diversity but only reducing unintended diversity which only hampers communication and not enhances it.
-
Sounds are considered only the syntax (or structure without meaning) of the language and semantics is something superimposed using vocabulary and rules which forms the grammar but in Sanskrit the sounds are not just the syntax but is also linked with semantics (which refers to communicating meaning) and effect (vibrational effect of sound on speaker and listener neurology).


